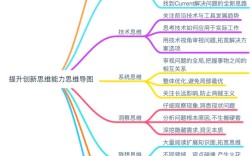
什么是计算思维?
计算思维是一种解决问题的方法论,它借鉴了计算机科学的精髓,核心是将一个复杂的大问题,分解成一系列可以理解、可以执行的小步骤,它包含以下几个核心要素:

-
分解
- 是什么:将一个复杂、庞大的问题拆解成多个更小、更简单、更易于管理的子问题。
- 为什么:解决小问题比解决大问题要简单得多,就像盖房子,你不会一下子就想好整栋楼,而是先设计结构,再打地基,然后砌墙、装修。
-
模式识别
- 是什么:在分解后的子问题中,寻找相似性、规律或重复出现的结构。
- 为什么:识别模式可以让我们避免重复劳动,一旦发现某个问题有规律,我们就可以用统一的、通用的方法来解决它,而不是为每个情况都写一套独特的方案。
-
抽象
- 是什么:忽略掉与当前问题无关的细节,只关注最核心、最重要的信息,将通用的解决方案提炼成一个“模型”或“概念”。
- 为什么:抽象能极大地简化问题,你不需要关心一辆汽车内部发动机的每一个零件,你只需要知道“踩油门它会加速,踩刹车它会停下”这个抽象接口就够了。
-
算法设计
- 是什么:为解决子问题设计一套清晰、准确、有限的步骤,这套步骤就是算法。
- 为什么:算法是指导计算机执行任务的“食谱”,它确保了无论输入是什么,只要按照步骤执行,就能得到预期的、正确的结果。
计算思维题实战演练
下面我们通过几道经典的题目,来实践这四个步骤。 一:过河问题
问题描述: 一个农民需要带一只狼、一只羊和一筐白菜过河,他有一条船,但船每次除了他自己,只能再多带一样东西。 限制条件:
- 如果农民不在,狼会吃掉羊。
- 如果农民不在,羊会吃掉白菜。 问题:农民如何才能将所有东西安全地带到对岸?
计算思维分析过程
分解
这个问题可以分解为一系列“状态”和“动作”。
- 状态:描述当前河两岸的情况。“农民、狼、羊、白菜都在左岸”是一个初始状态。
- 动作:农民可以进行的操作。“农民带狼去右岸”、“农民自己划船回左岸”等。
我们的目标是从初始状态,通过一系列合法的动作,达到“农民、狼、羊、白菜都在右岸”的最终状态。
模式识别
在尝试解决的过程中,你会发现一些模式:
- 来回运输:你不可能一次性把所有东西运过去,必然需要多次来回。
- 关键物品:羊是“麻烦制造者”,因为它既不能和狼单独在一起,也不能和白菜单独在一起,农民的很多动作都必须围绕羊来展开。
抽象
我们可以把问题抽象成一个状态图,每个“状态”是一个节点,每个“合法的动作”是连接两个节点的边,我们的任务就是在这个图中找到一条从“初始状态”到“最终状态”的路径。
- 抽象出核心元素:左岸有什么,右岸有什么,船在哪。
- 抽象出规则:哪些状态是“非法”的(如狼和羊单独在左岸)。
算法设计
现在我们可以设计一个“尝试并记录”的算法:
- 定义初始状态:左岸: {农民, 狼, 羊, 白菜}, 右岸: {}
- 循环:只要当前状态不是最终状态,就执行以下操作: a. 列出所有可能的合法动作。 b. 选择一个动作,并执行它,得到一个新状态。 c. 检查新状态是否合法,如果非法,回退,尝试下一个动作。 d. 记录路径:将这个动作添加到解决方案列表中。 e. 更新当前状态为这个新状态。
- 结束:当当前状态为最终状态时,循环结束,记录的路径就是解决方案。
最终解决方案(算法执行结果):
- 农民带羊过河。
左岸: {狼, 白菜}, 右岸: {农民, 羊}
- 农民自己返回。
左岸: {农民, 狼, 白菜}, 右岸: {羊}
- 农民带狼过河。
左岸: {白菜}, 右岸: {农民, 狼, 羊}
- 农民带羊返回。(这是关键一步!)
左岸: {农民, 羊, 白菜}, 右岸: {狼}
- 农民带白菜过河。
左岸: {羊}, 右岸: {农民, 狼, 白菜}
- 农民自己返回。
左岸: {农民, 羊}, 右岸: {狼, 白菜}
- 农民带羊过河。
左岸: {}, 右岸: {农民, 狼, 羊, 白菜}
任务完成!
烧水泡茶问题
问题描述: 假设你需要为客人烧水泡茶,你有以下工具和任务:
- 任务:喝茶
- 工具:茶壶、茶杯、火炉、水壶
- 步骤:
- 洗好水壶
- 灌上凉水
- 放在火上烧水
- 洗茶壶
- 洗茶杯
- 拿茶叶
- 水烧开后,泡茶 问题:如何安排这些步骤,才能最快地喝上茶?
计算思维分析过程
分解
将整个任务分解为原子步骤: A. 洗水壶 B. 灌水 C. 烧水 D. 洗茶壶 E. 洗茶杯 F. 拿茶叶 G. 泡茶
模式识别
- 依赖关系:有些步骤必须在另一些步骤之后才能进行。
G (泡茶)必须在C (烧水)之后。C (烧水)必须在A (洗水壶)和B (灌水)之后。
- 并行关系:有些步骤可以同时进行,互不干扰。
C (烧水)这个过程需要一段时间,但它不需要人一直盯着,在这段时间里,人可以去做其他事情。
抽象
我们可以将这个问题抽象成一个有向无环图,其中节点是步骤,边是“必须先做”的依赖关系。
A -> B -> C -> GD, E, F是独立的,但它们都指向G。
算法设计
算法的核心是识别可以并行执行的任务,以节省总时间。
- 执行必须顺序执行的任务:
- 洗水壶
- 灌水
- 开始烧水。
- 利用烧水的等待时间(并行执行其他任务):
- 在水壶烧水的同时,去洗茶壶。
- 在水壶烧水的同时,去洗茶杯。
- 在水壶烧水的同时,去拿茶叶。
- 执行烧水后必须执行的任务:
水烧开后,泡茶。
最终解决方案(算法执行结果):
- 洗水壶 (1分钟)
- 灌水 (1分钟)
- 烧水 (15分钟)
- 在这15分钟内,同时进行以下任务:
- 洗茶壶 (2分钟)
- 洗茶杯 (1分钟)
- 拿茶叶 (1分钟)
- (这些任务总耗时2分钟,远小于15分钟,所以可以全部完成)
- 在这15分钟内,同时进行以下任务:
- 泡茶 (1分钟)
总耗时 = 1 + 1 + 15 + 1 = 18分钟。
如果顺序执行,总耗时将是 1+1+15+2+1+1+1 = 22分钟,通过并行处理,我们节省了4分钟。
寻找丢失的数字
问题描述:
有一个包含 n 个不同整数的已排序数组 A,这个数组的范围是从 1 到 n+1,也就是说,如果数组有 5 个元素,那么它应该包含 1, 2, 3, 4, 5, 6 中的一个数字,并缺少其中一个。
A = [1, 2, 3, 5, 6],缺少了 4。
问题:如何高效地找出这个丢失的数字?
计算思维分析过程
分解
这个问题可以分解为:
- 输入:一个已排序的数组
A。 - 输出:一个丢失的数字
missing_num。 - 特性:数组元素是唯一的,范围是
[1, n+1],且已排序。
模式识别
- 理想情况:如果没有数字丢失,数组应该是
[1, 2, 3, ..., n],对于任意一个索引i(从0开始),A[i]的值应该是i + 1。 - 丢失数字的影响:一旦某个数字
x丢失了,x之后的所有数字都会向前移动一位,这意味着,对于x及其之后的数字,A[i]的值将不再等于i + 1,而是A[i] > i + 1。
抽象
我们可以利用这个模式来设计算法,问题被抽象为:在数组中找到第一个满足 A[i] != i + 1 的位置 i,丢失的数字就是这个位置上的值减一。
A = [1, 2, 3, 5, 6]:A[0] = 1(等于 0+1)A[1] = 2(等于 1+1)A[2] = 3(等于 2+1)A[3] = 5不等于3+1,第一个不满足条件的位置是i=3。- 丢失的数字就是
A[3] - 1 = 5 - 1 = 4。
算法设计
由于数组是已排序的,我们可以使用一种高效的搜索算法——二分查找。
- 初始化:设置两个指针,
left = 0,right = len(A) - 1。 - 循环:当
left <= right时: a. 计算中间索引mid = (left + right) // 2。 b. 检查A[mid]是否等于mid + 1。- 如果相等:说明丢失的数字在
mid的右侧,更新left = mid + 1。 - 如果不相等:说明丢失的数字在
mid的左侧(或者mid本身就是丢失数字的位置),更新right = mid - 1。
- 如果相等:说明丢失的数字在
- 确定结果:当循环结束时,
left指针指向的就是第一个不满足A[i] == i + 1的位置,丢失的数字就是A[left] - 1。- (如果丢失的是最后一个数字,
[1, 2, 3]缺少4,循环结束后left会指向len(A),此时结果就是len(A) + 1,需要特殊处理一下)
- (如果丢失的是最后一个数字,
最终解决方案(算法执行结果):
以 A = [1, 2, 3, 5, 6] 为例:
left=0,right=4,mid=2。A[2]=3等于2+1。left = 3。left=3,right=4,mid=3。A[3]=5不等于3+1。right = 2。- 循环结束 (
left > right)。 left的值是 3,丢失的数字是A[3] - 1 = 5 - 1 = 4。
这个算法的时间复杂度是 O(log n),比从头到尾遍历的 O(n) 要高效得多。
计算思维的核心在于“如何思考”,而不是“思考什么”,面对任何问题,尤其是复杂问题,都可以尝试用这四个步骤来梳理思路:
- 分解:把大象切成小块。
- 模式识别:看看这些小块有没有共同点。
- 抽象:忽略无关细节,抓住核心。
- 算法设计:为小块设计清晰的执行步骤。
多练习这类问题,你会发现自己分析问题、设计解决方案的能力会得到显著提升,如果你想挑战更多题目,可以搜索“算法题”、“逻辑谜题”或“脑筋急转弯”等关键词。